Hey, @TC 
If you have the time, could you kindly review the issue I’m having below?
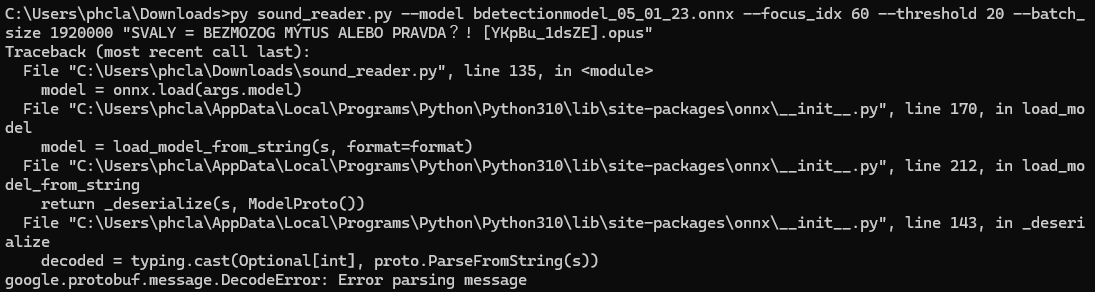
I started getting this error when I tried to run the tool on a video I’d downloaded:
Traceback (most recent call last):
File "C:\Users\phcla\Downloads\sound_reader.py", line 135, in <module>
model = onnx.load(args.model)
File "C:\Users\phcla\AppData\Local\Programs\Python\Python310\lib\site-packages\onnx\__init__.py", line 170, in load_model
model = load_model_from_string(s, format=format)
File "C:\Users\phcla\AppData\Local\Programs\Python\Python310\lib\site-packages\onnx\__init__.py", line 212, in load_model_from_string
return _deserialize(s, ModelProto())
File "C:\Users\phcla\AppData\Local\Programs\Python\Python310\lib\site-packages\onnx\__init__.py", line 143, in _deserialize
decoded = typing.cast(Optional[int], proto.ParseFromString(s))
google.protobuf.message.DecodeError: Error parsing message
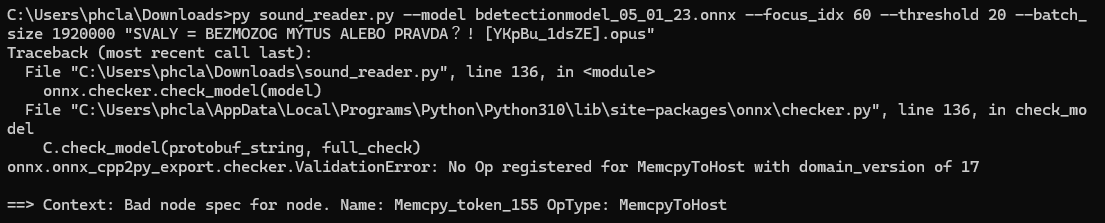
It seemed like something related to the model, so I redownloaded the .onnx model file you had here, and I was able to run one video. Then, when I tried to run the next one, I started getting the error below:
Traceback (most recent call last):
File "C:\Users\phcla\Downloads\sound_reader.py", line 136, in <module>
onnx.checker.check_model(model)
File "C:\Users\phcla\AppData\Local\Programs\Python\Python310\lib\site-packages\onnx\checker.py", line 136, in check_model
C.check_model(protobuf_string, full_check)
onnx.onnx_cpp2py_export.checker.ValidationError: No Op registered for MemcpyToHost with domain_version of 17
==> Context: Bad node spec for node. Name: Memcpy_token_155 OpType: MemcpyToHost
I also tried “pip install --upgrade” to see if anything was outdated, but it had no effect 
Would you happen to know what could be happening and how could I address this? Thanks in advance!
EDIT: After doing some digging, I found that apparently the Domain isn’t set to the following Nodes. It seems like some ONNX operations don’t require a Domain, and maybe the tool doesn’t even require these Nodes, but if either is the case, then maybe this could be related to the problem.
Node Name: Memcpy_token_155, OpType: MemcpyToHost, Domain:
Node Name: Memcpy_token_154, OpType: MemcpyFromHost, Domain:
Node Name: Memcpy, OpType: MemcpyFromHost, Domain:
I tried creating a copy of the Model for testing and reset the Domain to a random one (com.microsoft) just to see if I got something different, and got error “Fatal error: com.microsoft:MemcpyToHost(-1) is not a registered function/op”. So, I guess maybe these Nodes do need to have an empty Domain.
I also tried deleting them and got a sorting error (“C.check_model(
onnx.onnx_cpp2py_export.checker.ValidationError: Nodes in a graph must be topologically sorted, however input ‘/Transpose_1_output_0’ of node:
name: /conv_block1/Relu_output_0_nchwc OpType: Conv
is not output of any previous nodes.”), so I guess these Nodes do need to be there, and the problem is something else.
Just felt like sharing, in case it saves you any time when/if you have the time to check this out